Tarea Valuable T3
Investigación de entorno virtual para evaluar incidencia de la utilización de un nuevo entorno en las calificaciones de estudiantes que utilizan Google Apps y Moodle
Paso 1: En este primer paso se pide observar los datos y reflexionar acerca de la relación que existe entre las variables calificación, grupo y sexo.
Según lo que pude observar, los estudiantes que utilizan Google Apps tienen mejor calificación en comparación a los estudiantes que utilizan Moodle.
Para que se pueda entender mejor lo explicado, observar la imagen a continuación.

Ahora bien, a la observación, tomando en consideración las variables por sexo de ambas plataformas, por lo que se puede observar, tanto los estudiantes femeninos como masculino de Google Apps tienen mejor calificación que los de Moodle.
En la siguiente imagen se puede ver claramente.
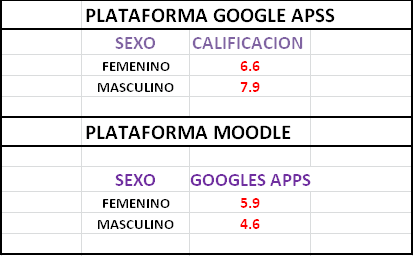
Paso 2:
Se muestra un gráfico de interacción de Excel o Google Sheets donde se combinan las medidas de las calificaciones de las variables, grupo y sexo, es decir, Moodle-Male, Moodle-Female, GoogleApps-Male, GoogleApps-Female.
¿Coinciden los resultados mostrados en el gráfico con tus reflexiones del apartado anterior?

Respondiendo a la pregunta más arriba, se puede evidenciar que los datos especificados, si coinciden con los datos reflejados en el gráfico.
Paso 3: Analizar si existen diferencias estadísticamente significativas en las calificaciones en función del grupo y del sexo
Para poder realizar el paso tres, haré un recuento de todo el proceso.
Ya en el programa RStudio, lo primero fue abrir la Base de Datos que contiene la información de los datos de este ejercicio, utilizando la línea de comando que se muestra más abajo.
Datos3 <- read.csv("C:/Users/Lucia/Desktop/MASTER/Asignaciones finales/T3/Notas-2grupos-v3.csv", sep=";")
> View(Datos3)

En el siguiente paso, ya para poder dividir los datos en función del grupo y el sexo, utilicé los siguientes comandos, con el cual se puede ver con claridad que son 20 estudiantes de Moodle, la misma cantidad muestra para los estudiantes de Google apps. En general hay 20 masculino y 20 femenino entre las dos plataformas.
a) Datos en Moddle
Datos3Moodle <- subset(Datos3, grupo=="Moodle")
b) Datos en Google Apps
Datos3GoogleApps <- subset(Datos3, grupo=="Google Apps")
c) Datos Masculino
Datos3Masculino <- subset(Datos3, sexo=="M")
d) Datos Femenino
Datos3Femenino <- subset(Datos3, sexo=="F")

Para el paso tres el cual pide comparar los datos y verificar si existen diferencias significativas en las calificaciones, dividido por grupo y Sexo.
El análisis de los datos se refleja que sí existen diferencias significativas entre los dos grupos, tal y como se muestra en los datos suministrados más abajo.
Según lo que pude interpretar, el margen de error es menor de un 5%, con relación al
p-value = 1.683e-06, ósea, 0.000001683, esto equivale a 0.00001683%.
t.test(Datos3Moodle$nota, Datos3GoogleApps$nota)
data: Datos3Moodle$nota and Datos3GoogleApps$nota
t = -5.6569, df = 38, p-value = 1.683e-06
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.715731 -1.284269
sample estimates:
mean of x mean of y
5.25 7.25

Ahora se muestran la comparación por sexo :
t.test(Datos3Masculino$nota, Datos3Femenino$nota)
Welch Two Sample t-test
Data: Datos3Masculino$nota and Datos3Femenino$nota
t = 0, df = 28.082, p-value = 1
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.982814 0.982814
sample estimates:
mean of x mean of y
6.25 6.25

Analizando los datos por sexo, se puede observar que no hubo diferencias estadísticamente significativas entre los estudiantes, ya que el margen de error es mayor que un cinco por ciento, en virtud de que p-value =1, lo que equivale a un 100%.
4.- Utilizar la función aov() de R para saber si existe una interacción estadísticamente significativa entre las variables grupo y sexo.
Para ello daré una descripción detallada de cómo utilicé la variable (aov), y así poder mostrar el grado de interacción entre las variables

La función aov() necesita que sea pasada por argumento en primer lugar la variable dependiente, seguida del símbolo “~” y posteriormente las dos variables independientes separadas por un “*”.summary(aov(Datos3$nota ~ Datos3$grupo*Datos3$sexo)) Df Sum Sq Mean Sq F value Pr(>F) Datos3$grupo 1 40.0 40.00 47.06 5.02e-08 ***Datos3$sexo 1 0.0 0.00 0.00 1 Datos3$grupo:Datos3$sexo 1 16.9 16.90 19.88 7.74e-05 ***Residuals 36 30.6 0.85 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Por lo que pude analizar en los resultados hay una interacción estadísticamente significativa entre las variables grupo y sexo, puesto que el valor de p es de 7.74e-05, lo que equivale a 0.0000774, lo que es igual a un 0.00774%.



No hay comentarios:
Publicar un comentario